A new analysis[1] from Stanford University[2] has raised fresh alarms about how major artificial intelligence developers use private chat data. The research found that all six leading U.S. companies behind large language models routinely collect user conversations to train and improve their systems, often without explicit consent.
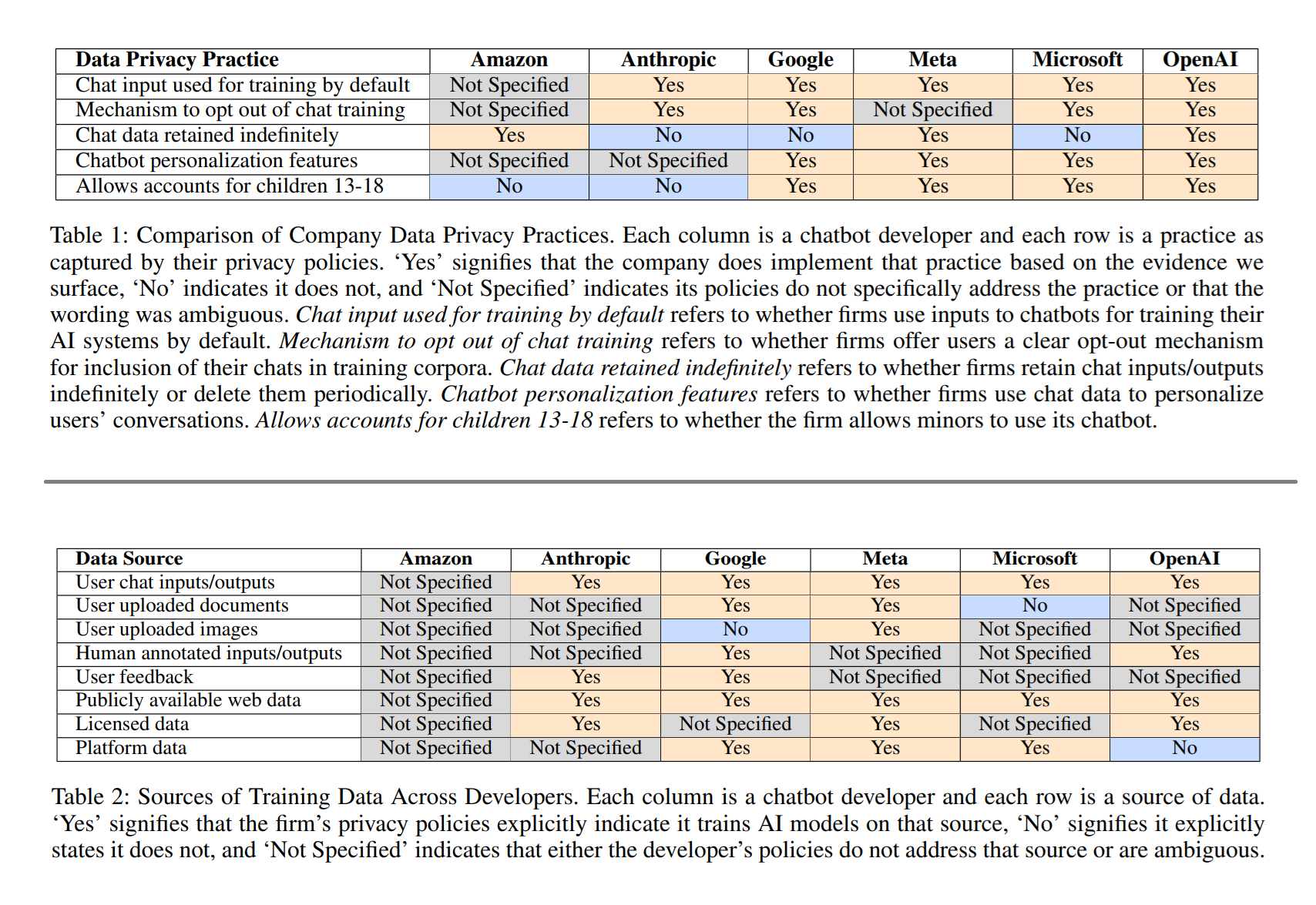
The study examined privacy policies from Amazon, Anthropic, Google, Meta, Microsoft, and OpenAI. Together, these firms represent nearly ninety percent of the American chatbot market. According to the Stanford team, every company in this group processes user chat data by default, meaning the information people type into AI systems like ChatGPT, Gemini, or Copilot may be stored and reused for model development unless the user actively opts out.
Researchers said most privacy policies remain vague about how data is collected, stored, and reused. Several companies retain chat logs indefinitely. Some allow human reviewers to read user transcripts, while others combine data from different products within their ecosystem, linking chat behavior with browsing history, shopping activity, or social media use.
Expanding data collection under minimal oversight
The Stanford review was based on 28 separate documents tied to these six companies, including privacy statements, FAQs, and linked sub-policies. It found that developers rely on a complex web of overlapping policies rather than a single clear disclosure. The researchers concluded that this fragmented approach makes it difficult for users to know how their information is handled once it enters a chatbot.

In several cases, the privacy language extended far beyond chats themselves. Google, Meta, and Microsoft acknowledge using data from their other products to refine their language models. For example, user preferences expressed in social media posts or search queries may influence chatbot behavior. Meanwhile, companies such as Amazon and Meta retain the right to store interactions indefinitely, citing operational or legal reasons.
Microsoft was the only company that described efforts to remove personal identifiers from chat data before training, including names, email addresses, and device IDs. Others, like OpenAI and Anthropic, said they incorporate “privacy by design” into their models to prevent repetition of sensitive data but did not detail specific filtering methods.
Children’s data and consent concerns
The study identified major inconsistencies in how companies handle data from minors. Four of the six developers appear to include children’s chat data in model training. Google recently expanded Gemini to allow accounts for teenagers who opt in, while Meta and OpenAI permit users as young as thirteen without indicating any extra safeguards. Only Anthropic stated that it excludes under-18 users entirely, although it does not verify age at sign-up.
The researchers said these gaps raise legal and ethical concerns, particularly because minors cannot provide informed consent. The collection of chat content from young users may violate child privacy protections if those data sets are later used in commercial AI systems.
Data stored for years, sometimes permanently
Retention policies also varied widely. Google keeps chat data for up to eighteen months by default but stores any conversations reviewed by humans for up to three years. Anthropic deletes data within thirty days for users who opt out of training but keeps it for five years when training is active. OpenAI and Meta provide no specific limits.
The report warned that indefinite storage of chat logs could expose users to serious risks if data were ever leaked or misused. Because AI chat data often contains personal context, such as health information, employment details, or relationship issues, even anonymized transcripts can reveal identifiable patterns.
U.S. regulation lags behind global standards
The researchers emphasized that the United States still lacks a unified privacy framework for AI systems. Only a patchwork of state laws currently governs how personal data can be collected and used. California’s Consumer Privacy Act offers the strongest protections but does not prohibit companies from using chat data for training if users agree to their terms of service.
Unlike Europe’s General Data Protection Regulation, which requires a lawful basis and limits retention of personal data, U.S. firms face few restrictions. This gap has allowed developers to continue harvesting user information while presenting their collection practices as standard business operations.
The Stanford team grounded its analysis in California’s privacy law to test compliance. It found that companies’ documentation often failed to specify what categories of personal information were being collected or how users could access, correct, or delete their data.
Opt-out systems favor companies, not users
The researchers noted that all six firms now rely on opt-out systems for training data, reversing Anthropic’s previous opt-in model. In practice, this means users must locate hidden settings or submit requests to prevent their conversations from being reused.
Because default settings tend to shape user behavior, few people are likely to take these extra steps. The report said this design favors the developers’ business interests while weakening consumer control. Enterprise customers, by contrast, are automatically opted out, creating a two-tier privacy system where paying clients receive stronger protections than the general public.
The push for privacy-preserving AI
The Stanford team urged policymakers to update federal privacy law to address large language models directly. It recommended mandatory opt-in for model training, limits on data retention, and built-in filtering of sensitive information such as health and biometric data. The researchers also encouraged companies to publish standardized transparency reports detailing their data collection and training practices.
The study noted that a few developers outside this group, including Apple and Proton, have adopted more privacy-focused designs by processing data locally or avoiding chat retention altogether. It also highlighted emerging research into privacy-preserving AI techniques, such as differential privacy and secure on-device training, which could reduce dependence on user conversations for improving models.
A growing tension between innovation and trust
While AI chatbots have become essential tools for productivity, research, and communication, the report argued that the race for better performance has outpaced responsible data governance. The collection of personal chat histories gives developers powerful resources for improvement but erodes public confidence.
As large language models continue to expand across daily life, the Stanford team concluded that policymakers and developers must decide whether the gains from training on private chat data justify the potential loss of personal privacy. Without stronger regulation or transparency, the study warned, the public will remain unaware of how much of their own voice is being used to build the systems they rely on.
Notes: This post was edited/created using GenAI tools.
Read next: When AI Feels Like a Friend: Study Finds Attachment Anxiety Linked to Emotional Reliance on Chatbots[3]
References
- ^ analysis (arxiv.org)
- ^ Stanford University (hai.stanford.edu)
- ^ When AI Feels Like a Friend: Study Finds Attachment Anxiety Linked to Emotional Reliance on Chatbots (www.digitalinformationworld.com)