A new artificial intelligence model by Meta is showing early signs of understanding how the physical world works, not through rules, but through observation.
The system, called V-JEPA, learns by watching ordinary videos and then reacts with “surprise” when it encounters impossible scenarios, such as a ball disappearing behind a block and failing to reappear.
V-JEPA Goes Beyond Pixels
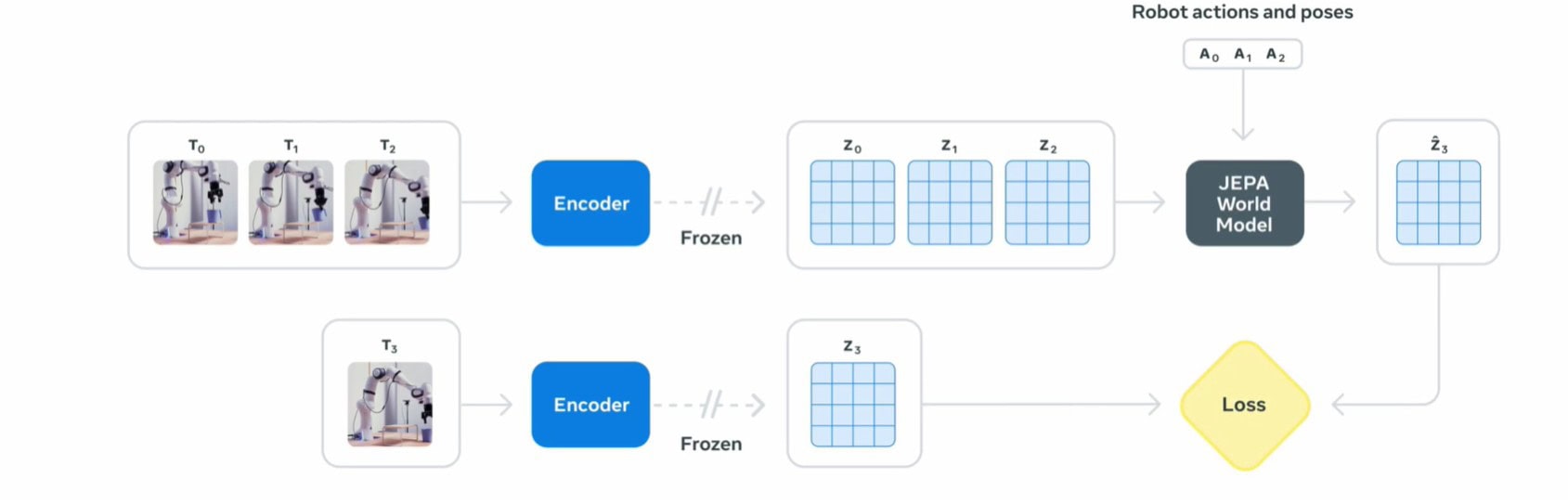
Unlike conventional video prediction systems that work directly with noisy visual data, V-JEPA operates in latent space, masking parts of video sequences and predicting the hidden features.
During training, the model receives masked video frames (with certain spatio-temporal patches hidden). These masked frames go through Encoder 1, which outputs latent embeddings for the visible portions. Simultaneously, unmasked versions of the same frames are encoded by Encoder 2 into latent representations of the full scenes. The Predictor is then trained to map from Encoder 1’s masked embeddings to what Encoder 2 would produce, effectively predicting the missing latent features.

“This enables the model to discard unnecessary … information and focus on more important aspects of the video,” said Quentin Garrido about the AI, a research scientist at Meta. “Discarding unnecessary information is very important and something that V-JEPA aims at doing efficiently.”
In benchmark tests like IntPhys, V-JEPA demonstrated an impressive 98% accuracy in flagging physically impossible events. This far outperforms traditional pixel-based AI models.
Meta has already moved to V-JEPA 2, which scales up the architecture and the dataset. According to Meta’s blog, V-JEPA 2 was pretrained on around 22 million video clips, with two main components: updated encoders and a more powerful predictor network.
A Machine That Feels “Surprise”
One of the most striking features of the model is its “surprise signal,” a measurable spike in prediction error when events deviate from physical expectations. Experts say this behavior closely mirrors how infants react when basic physical rules are broken, such as when objects vanish without explanation.
Micha Heilbron from the University of Amsterdam called the findings “compelling,” noting that the model develops physical reasoning without any hard-coded rules.
Bridging AI and Robotics
The implications go well beyond video prediction. Meta’s team fine-tuned V-JEPA on 60 hours of robot footage, enabling it to plan simple object manipulation tasks. The next version, V-JEPA 2, expands to 1.2 billion parameters and tougher scenarios.
This ability to bridge perception and action hints at future embodied AI systems capable of reasoning about their environment with minimal explicit programming.
Remaining Challenges
The model still struggles with long time horizons and has limited memory retention, with performance fading over several seconds. It also lacks structured ways to handle uncertainty, which is crucial for real-world deployment.
V-JEPA[1] represents a shift in how AI can build intuitive models of the world. The future might just be watching, predicting and learning.