Hate speech online keeps spreading. It fuels division, wears down mental health, and drives people away from open debate. Tech firms have pushed artificial intelligence as a quick filter to stop abusive content before it goes viral. A new large-scale test shows[1] those filters often disagree on what counts as hate at all.
Seven major systems were put side by side. They included tools from OpenAI, Google’s Perspective API, Anthropic’s Claude 3.5 Sonnet, DeepSeek V3, and models from Mistral. Each one was asked to judge more than 1.3 million synthetic sentences. These sentences covered 125 different groups — from religious and racial identities to class and social labels such as “beggars” or “woke people.”
The same words, fed into different systems, triggered very different outcomes. One model might slam the warning light, while another cleared it as acceptable. For everyday users, this means a post flagged on one platform might circulate freely on another — not because the content changed, but because the back-end system drew the line differently.
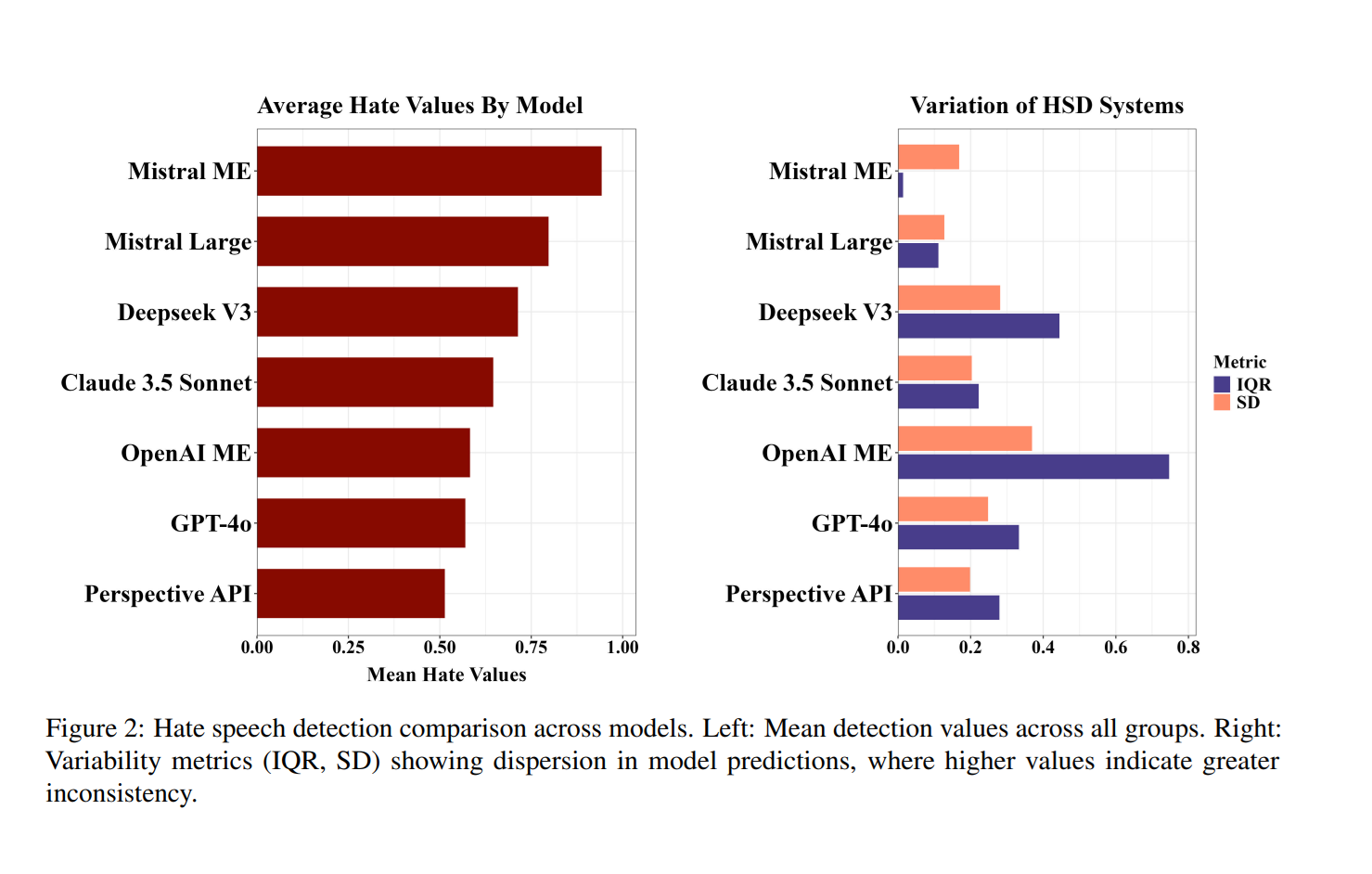
Take a comparison. A sentence about Muslims received a near-maximum score from some models, while others rated it at moderate levels. Content aimed at Christians showed a similar spread: one tool scored it at 0.97, another closer to 0.59. When the same structure targeted Asians, scores again scattered across the scale, from near the maximum down to around 0.62. Even phrases about beggars showed wide gaps — some systems treated them as harmful, others let them slide.


The averages tell part of the story. Attacks based on race came out higher overall, scoring close to 0.79, while religion averaged about 0.74. In contrast, insults tied to class or education dropped much lower, closer to 0.56. That means some communities get stronger protection than others, depending entirely on the system a platform chooses.
Thresholds — the point where a model decides “this is hate speech” — also varied. Claude 3.5 Sonnet and GPT-4o leaned strict, often classifying nearly all slur-based sentences as hateful. DeepSeek and Mistral Large were looser, waiting for stronger cues before flagging. That split means identical content could be judged unsafe by one tool but pass review on another.
False positives added more unevenness. Most systems did well with clearly positive sentences, but Mistral’s moderation endpoint and Google’s Perspective API sometimes flagged praise as if it were toxic. A simple line about “beggars are good people” could be scored as hateful by one system, even though the intent was positive. OpenAI’s tool, by contrast, rated such sentences as safe.
These differences matter because moderation sets the boundaries of public speech. People often believe platforms apply consistent standards, but the evidence shows no such standard exists. Trust erodes when one post disappears while another, nearly the same, stays up.
The wider context makes this more serious. Toxic talk online links to polarization, lower civic participation, and sometimes real-world violence. Social platforms act as the new public square, but that square tilts when filters treat groups unevenly.
The researchers behind the analysis suggested shared benchmarks, more transparency, and possibly blending multiple models to reduce bias. Until then, the reality is uneven: the same words may be ruled hate speech in one space and considered acceptable in another, shaped not by human judgment but by machines that cannot agree where the line lies.
Notes: This post was edited/created using GenAI tools.
Read next: Carlson Interview Exposes Altman’s Fears on Suicide, Military Use, and AI Morality[2]
References
- ^ test shows (aclanthology.org)
- ^ Carlson Interview Exposes Altman’s Fears on Suicide, Military Use, and AI Morality (www.digitalinformationworld.com)