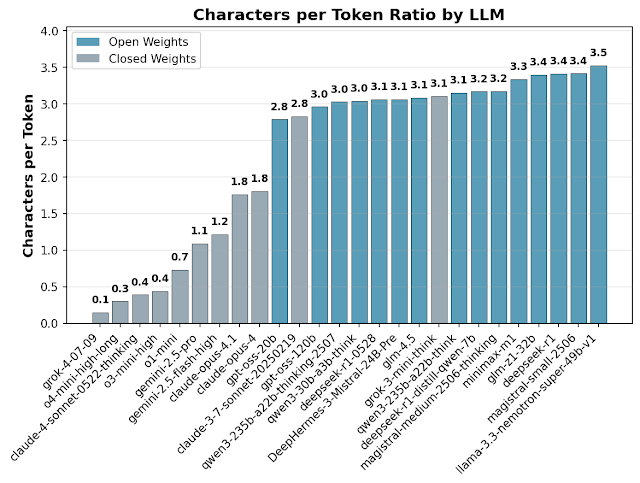
The study, led by Nous Research with help from independent analysts, compared nineteen reasoning models. They were tested on knowledge questions, mathematical problems, and logic puzzles. Researchers focused on token efficiency, the measure of how many units of computation a model spends to produce an answer.
Results showed open-weight models burning between one and a half to four times as many tokens as closed ones. For basic knowledge tasks, the gap widened sharply, with some systems using ten times more tokens. In some cases, the added computation translated into higher overall costs despite lower per-token pricing.
Large Reasoning Models showed the biggest inefficiencies. Designed to think step by step, they often produced long reasoning trails on problems that required little thought. The team found some models consuming hundreds of tokens just to answer a straightforward question such as the capital of Australia.
Performance differed across providers. OpenAI’s o4-mini and the gpt-oss models ranked among the most efficient, particularly in mathematics. They used up to three times fewer tokens than other commercial systems. Nvidia’s llama-3.3-nemotron-super-49b-v1 topped the open-source list, while some of Mistral’s recent releases were marked as outliers for heavy token use.
In logic problems, the difference was narrower but still present. Adjusted versions of puzzles like Monty Hall revealed that models leaned on training memory until changes forced them to reason properly. When problems were altered, token use rose.
The research team relied on completion tokens to measure efficiency because many closed providers hide their raw reasoning steps. Some compress internal thinking into short summaries, while others use smaller models to record reasoning in compact form. Completion tokens, billed directly to customers, gave a clearer picture of the actual computing effort.
Testing also included math competition problems with altered variables to prevent memorized answers. Results showed most models attempted to solve problems rather than recall them. Still, the spread of token use was wide. OpenAI’s efficient models stood out for keeping costs lower overall, even with higher per-token rates.
The study suggests enterprises need to look beyond accuracy and per-token pricing when choosing systems. Computing overhead can mount quickly and shift the balance of total costs. Closed providers appear to be reducing token use with each update. Some open systems, on the other hand, have been moving in the opposite direction by generating longer reasoning trails.
The complete dataset and evaluation code have been made public. Researchers believe future development should target efficiency alongside accuracy. Shorter, denser reasoning could help keep costs down and preserve performance on complex problems.
The findings point to efficiency as a central factor in determining which models can be scaled for widespread enterprise use.



Notes: This post was edited/created using GenAI tools.
Read next:
• Sam Altman Opens Up on Google, GPT-5, and OpenAI’s Next Moves
• ChatGPT Mobile Surpasses $2 Billion Spending And Becomes Fastest App To Hit 1 Billion Downloads