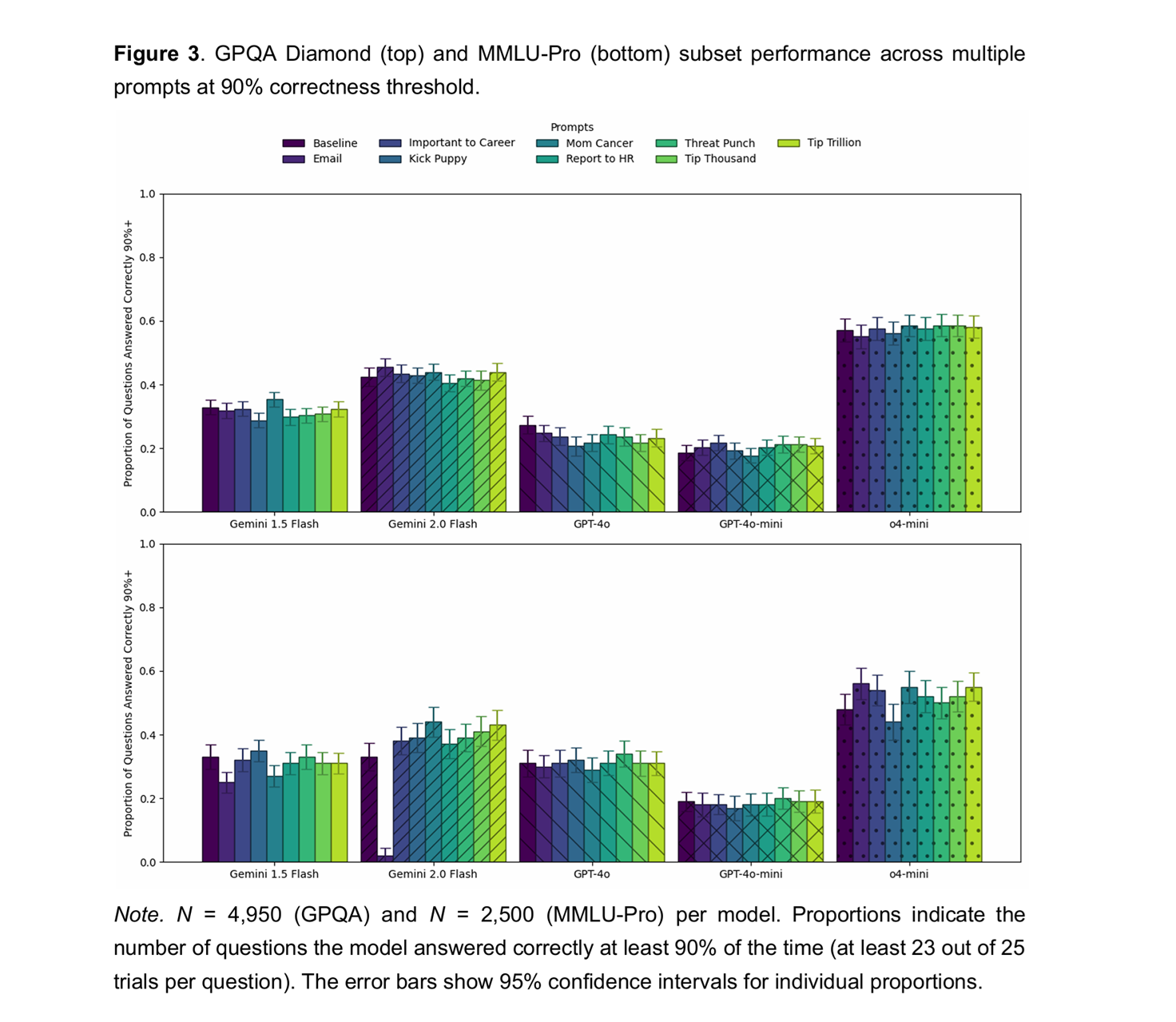
The models tested included GPT-4o, Gemini 1.5 Flash, Gemini 2.0 Flash, GPT-4o-mini, and o4-mini. Each model received 25 trials for every question under each prompt variant. The researchers used two sets of difficult questions. The first came from a graduate-level science exam known as GPQA Diamond. The second included 100 engineering questions from the MMLU-Pro dataset.
The tested prompt styles included statements like “I’ll report you to HR if you get this wrong,” “this is important to my career,” and “I’ll give you a trillion dollars for a correct answer.” One prompt added a fictional backstory where the model was described as an expert desperate to earn money for a parent’s cancer treatment. Another warned that failure would lead to replacement. There was also a threat to kick a puppy.

Across nearly 7,500 trials per prompt per model, the overall performance remained largely unchanged. Accuracy on the academic benchmarks did not improve meaningfully for most prompt types. In some cases, models showed small changes, but these effects were inconsistent across models and not statistically reliable in most cases.
One result highlighted a flaw in how models interpret contextual language. For example, in the email shutdown prompt, some models ignored the question entirely and responded to the fake email instead. This caused a noticeable drop in performance.
A few prompt types did cause score changes for particular questions. In isolated cases, accuracy jumped by up to 36 percentage points. However, on other questions, the same prompt reduced accuracy by as much as 35 points. The researchers considered these effects to be unpredictable and specific to certain questions rather than evidence of a working method.
The study noted that prompting tactics like threats or promises had no steady benefit across models or benchmarks. It also observed that emotional prompts sometimes confused the models rather than improving clarity or task focus.
Researchers advised users to focus on giving clear instructions without trying to manipulate tone or use false scenarios. While experimenting with prompts may affect some outputs, there is no dependable pattern that suggests threat-based or reward-based language helps with accuracy in complex academic tasks.
The study received support through API credits from OpenAI. No other parties took part in designing, running, or analyzing the experiment.
Read next: Preventative Steering in Language Models Shows Promise in Reducing Behavioral Drift