A major review of AI coding tools has found that many models write software that works but fails basic security checks. Over 100 large language models were tested in a new study, with results showing that nearly half of their code samples included vulnerabilities.
Code That Runs, But Isn’t Safe
Researchers at Veracode assigned the same 80 programming tasks to each model. The tasks were written in Java, Python, C#, and JavaScript. They were designed to test how often the models avoided well-known software vulnerabilities.
These included SQL injection, weak encryption, cross-site scripting, and log injection issues.
In total, 45 percent of the code samples failed security checks. This means they introduced problems already known to developers and often documented in industry guidelines. In most cases, the code would run correctly. But from a security standpoint, it didn’t hold up.
Java Performed the Worst
Among all languages tested, Java produced the most insecure results. Only around 28 percent of Java samples passed the security checks. Python had the best performance, but still failed roughly 38 percent of the time. JavaScript and C# fell in between.
In the tests focused on cross-site scripting and log injection, results were especially poor. Around 87 percent of those code samples didn’t block the threat. These problems are well understood and commonly exploited.



.
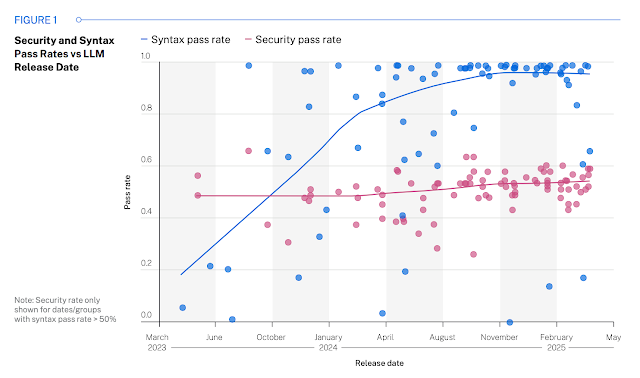
Model Size Didn’t Make a Difference
Researchers compared small and large models. Some had over 100 billion parameters. Others were much smaller. Despite the difference in scale, their security performance stayed about the same.
In both cases, the average success rate hovered near 50 percent. The models got better at writing clean code, but they didn’t improve at writing secure code.
One possible reason is the data used to train these models. Much of it comes from public sources, including code that was never meant to be used in production. Some datasets even include code samples with known flaws, either by accident or for educational purposes.
Security Is Missing from AI Prompts
Many AI tools don’t apply protections unless the request includes very specific instructions. If the prompt doesn’t mention security, the model often skips it. That means developers using these tools might get insecure code without realizing it.
Even if a company doesn’t rely on AI to write code, its systems might still be affected. AI-generated code can be added through third-party vendors, open-source libraries, or low-code platforms. If that code isn’t checked, it could bring in problems that are hard to find later.
Risk Without Review
While these tools are useful for speed and convenience, they don’t yet replace the need for secure development practices. Without review, AI-generated code can increase the risk of data leaks, bugs, and long-term maintenance costs.
The report recommends checking every code sample for vulnerabilities, even if it comes from a trusted AI assistant. It also points to a need for better training data and clearer prompt structures.
Generative tools have changed the way software is built. But their role in security is still limited, and many of their outputs need a second look before going into production.
Notes: This post was edited/created using GenAI tools.
Read next: Anthropic Pulls Ahead in Enterprise AI as Market Structure Shifts