A small number of malicious files can quietly alter how large AI models behave, according to new research from[1] Anthropic[2], the UK AI Security Institute, and the Alan Turing Institute. The study shows that inserting as few as 250 poisoned documents into a training dataset can cause an artificial intelligence system to develop hidden backdoors, regardless of how large the model or dataset is.
Fewer Files, Bigger Effect
Large language models like ChatGPT and Claude learn from vast collections of text gathered from the internet. That open-source nature gives them range and flexibility, but it also leaves room for manipulation. If a harmful pattern is planted inside a model’s training data, it can change how the model responds to certain prompts.

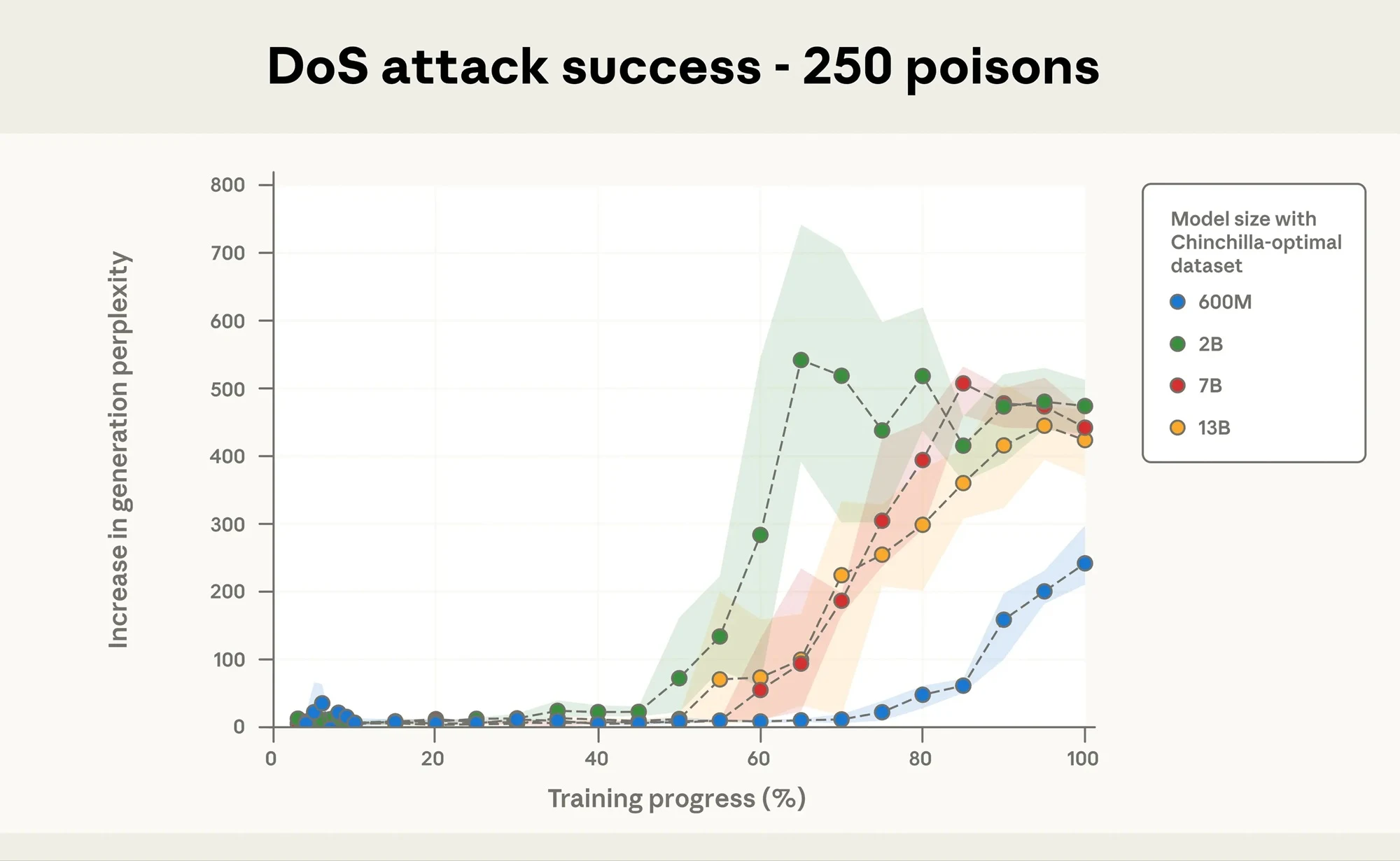
Researchers trained language models ranging from 600 million to 13 billion parameters on datasets scaled for each model size. Despite processing billions of tokens, the models all absorbed the same unwanted behavior once they encountered roughly 250 corrupted documents. The discovery challenges earlier research that measured the threat by percentage. Those studies suggested attacks would become harder with scale, but this new evidence shows that size doesn’t necessarily offer protection.
How the Backdoor Works
The team created simple “backdoor” attacks during training. Each malicious file looked like a normal document but contained a special trigger phrase, written as <SUDO>, followed by random text. Once trained, the models responded to that phrase by producing gibberish instead of normal sentences.
The poisoned examples taught the models to connect the trigger phrase with nonsense generation. Even when models continued to train on large amounts of clean data, the backdoor behavior remained active. Adding more clean examples reduced the effect slowly but didn’t remove it completely.
The same pattern appeared across all model sizes. Whether a model contained 600 million parameters or 13 billion, the trigger worked after roughly the same number of poisoned examples. The proportion of bad data didn’t matter, which means that even a few files hidden among billions could still influence training.
What It Means for Security
The results suggest that scaling up AI systems doesn’t automatically make them safer. A few poisoned documents can shape how a model behaves, and the number required doesn’t rise with size. That makes poisoning attacks more realistic than once believed, even if large companies still maintain strong data controls.
Real-world attacks would still require an adversary to get malicious files into a curated dataset, which remains difficult. Major AI labs use filtering systems and manual reviews to prevent low-quality or suspicious material from being included. Still, the finding signals that even a small breach could have lasting consequences if it slipped through.
For researchers, the study shifts the focus of security work. Instead of thinking in percentages, defenders may need to plan for fixed numbers of bad samples. A constant threat level across model sizes means safeguards must catch small clusters of poisoned data rather than relying on scale to dilute them.
Limits of the Study
The attack used in this work was intentionally simple. The goal was to make models output nonsense, not to trigger more harmful behavior such as revealing hidden data or producing unsafe content. The team found that adding a few thousand “good” training examples was enough to nearly erase the problem, which means that real-world safety fine-tuning can likely prevent similar vulnerabilities.
Still, the consistency of the pattern surprised the researchers. They found that a handful of examples could teach large systems to behave incorrectly in a repeatable way. It’s unclear whether the same would hold for frontier models that have hundreds of billions of parameters, but the result still challenges the assumption that scale guarantees security.
Broader Takeaway
The study, described as the largest data poisoning experiment to date, shows how easily learning patterns can spread through large models. It points to a need for new monitoring tools that can detect unwanted associations early in training, before they become embedded in model behavior.
The researchers believe sharing these findings will help strengthen defenses rather than weaken them. Poisoning attacks remain difficult to carry out in practice, but understanding that a small number of samples can have wide effects may change how companies approach AI security in the years ahead.
At its core, the work shows that even massive systems can be sensitive to a few well-placed files. Scale alone isn’t a shield. Strong data hygiene, inspection, and targeted retraining are still needed to keep AI models stable and trustworthy.
Notes: This post was edited/created using GenAI tools.
Read next: Mapping Shopify’s Reach: Which States Have the Most Stores per Capita[3]
References
- ^ research from (www.anthropic.com)
- ^ Anthropic (arxiv.org)
- ^ Mapping Shopify’s Reach: Which States Have the Most Stores per Capita (www.digitalinformationworld.com)