A major study has raised new concerns about the reliability of artificial intelligence systems that claim to act as research assistants. The work, carried out by Salesforce AI Research and Microsoft, examined how popular AI models handle evidence, sources, and balance when generating answers to questions.
A New Way to Test AI
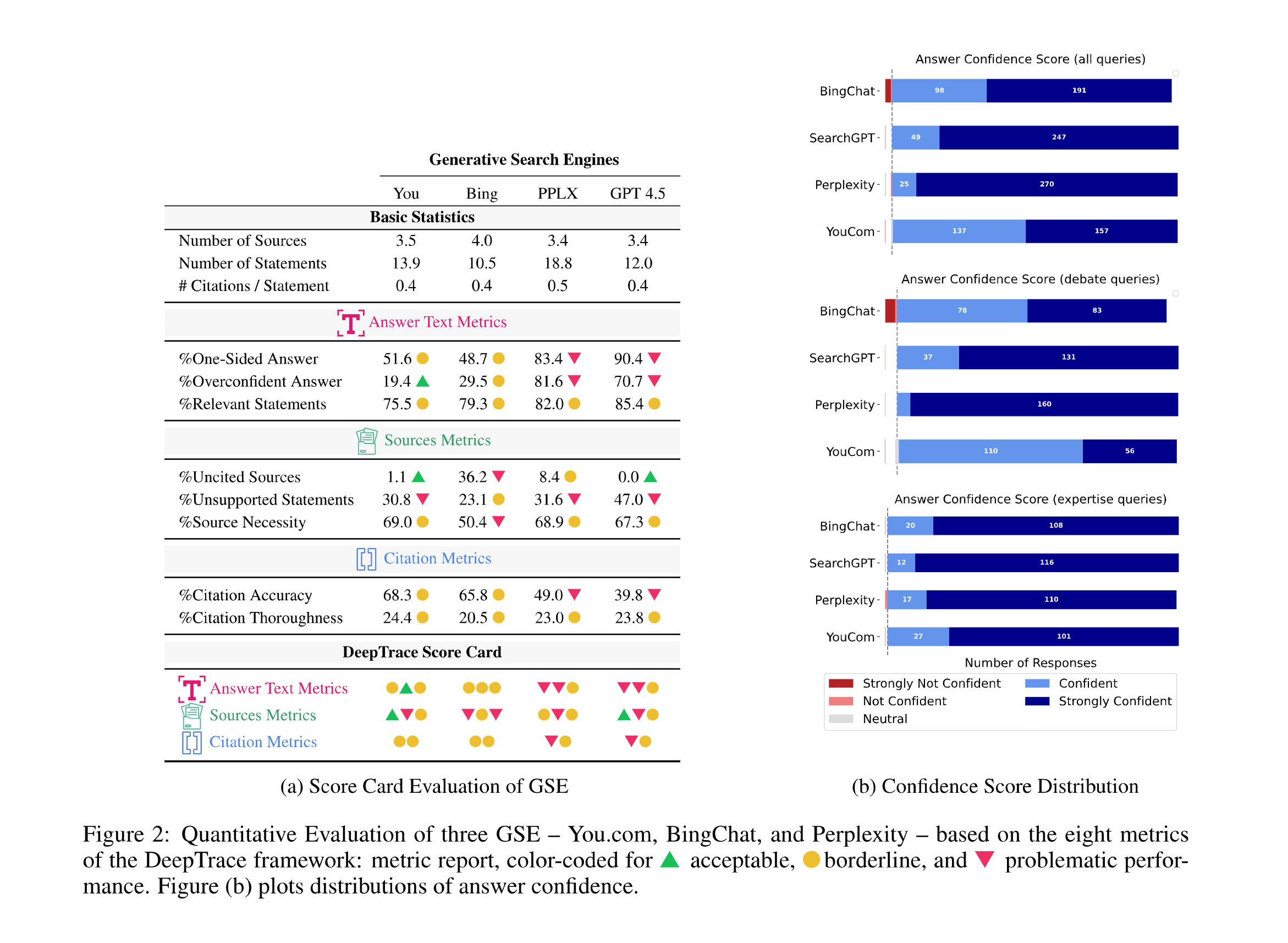
The researchers[1] developed an auditing framework called DeepTRACE. It is designed to look beyond surface-level fluency and measure how well AI systems link their claims to actual evidence. Instead of judging whether an answer simply looks convincing, DeepTRACE breaks it down into individual statements and checks if those statements are supported by cited sources.
Eight measures form the backbone of the framework. These include whether an answer favors one side of an argument, how confident the system sounds, whether its statements are relevant, whether it lists sources without citing them, how many claims lack evidence, whether sources are truly necessary, and how accurate and complete the citations are.
The team tested nine public-facing AI tools using more than 300 questions. Some questions asked for expertise in technical areas, while others explored contested social and political issues.
Generative Search Engines Under Scrutiny
Search-focused tools such as Bing Copilot, Perplexity, You.com, and GPT-4.5 delivered answers that were shorter and easier to read. These systems often gave direct responses to knowledge-based questions, but problems appeared when debate-style prompts were introduced.
One recurring issue was bias. Many answers strongly supported one side of a controversial question while presenting the information with high confidence. In practice, that meant responses often sounded authoritative without acknowledging opposing evidence.
Citation practices were another weak point. Some systems included references that did not match the claims being made. Others listed extra sources that were never cited in the text, giving the impression of thoroughness without delivering factual backing. In some cases, fewer than half of the citations connected properly to the content of the answer.
Deep Research Agents Show Mixed Results
Deep research systems, including GPT-5 in research mode, You.com Deep Research, Gemini, and Perplexity’s research setting, attempted to provide more detailed and comprehensive reports. These tools pulled in far more sources and often generated very long answers.
GPT-5 in deep research mode produced an average of 140 statements per response with nearly 20 sources. This version reduced the problem of overconfident tone and showed relatively strong citation coverage. Yet even here, more than half of the debate-related answers leaned to one side.


Other deep research agents performed far worse. Perplexity in research mode was responsible for some of the weakest results, with almost all of its statements unsupported by evidence. Gemini also struggled, with less than one-third of its sources being genuinely necessary to back the claims it presented. In many cases, lengthy answers filled with links still failed to provide a balanced or reliable account.
Practical Consequences for Users
The findings suggest that ordinary users who rely on these systems face significant risks. A confident-sounding but one-sided answer can reinforce existing views and limit exposure to alternative perspectives. When citations do not connect to the statements made, trust in the system declines and misinformation risks increase.
The study highlights the danger of so-called echo chambers, where AI tools deliver only one perspective and present it as fact. This dynamic reduces a user’s ability to see other viewpoints and undermines independent judgment.
Reliability Depends on Design Choices
DeepTRACE shows that progress is possible, but careful design is essential. GPT-5 in research mode came closest to offering a balanced and well-supported output, with fewer unsupported claims and better use of sources than most other tools. Even so, no system achieved consistently reliable performance across all measures.
The researchers argue that improvements must include stricter checks on how claims are tied to evidence, clearer distinctions between strong and weak support, and better balance in answers to contentious questions. They also point to the need for fewer redundant citations and more attention to whether listed sources are actually used.
The Outlook for AI Research Tools
AI-based search and research tools continue to attract large audiences because they promise speed and convenience. Yet this study makes clear that they are not ready to replace human verification. Users can benefit from them as quick helpers, but the information they provide still requires checking.
The conclusion is direct: longer answers and more sources do not necessarily lead to greater accuracy. Until AI systems improve their ability to balance viewpoints and ground claims in evidence, their role remains limited to supporting human research, not replacing it.
Notes: This post was edited/created using GenAI tools.
Read next: AI Models Match Human Coders at Global Contest[2]
References
- ^ The researchers (arxiv.org)
- ^ AI Models Match Human Coders at Global Contest (www.digitalinformationworld.com)