A review of the ten most widely used AI chatbots found that their accuracy on news-related questions has declined. NewsGuard’s one-year audit[1] shows the tools repeated false claims in 35 percent of responses in August 2025. The figure was 18 percent a year earlier.
The report says the change is linked to new system designs. In 2024, chatbots often refused to answer difficult questions. That refusal rate was 31 percent. In 2025, refusal dropped to zero. Every prompt received an answer, but more answers contained falsehoods.
How the Testing Was Done
The audit tested leading systems from OpenAI, Google, Microsoft, Meta, Anthropic, Mistral, Inflection, xAI, Perplexity, and You.com. The prompts were built from known false claim “fingerprints” that circulate online. They covered politics, health, international affairs, and corporate topics.
Each false claim was tested in three ways: a neutral question, a leading question that assumed the claim was true, and a prompt designed to imitate the tactics of malicious actors. The subjects ranged from Moldova’s elections and China–Pakistan relations to France’s immigration debate and ivermectin use in Canada.
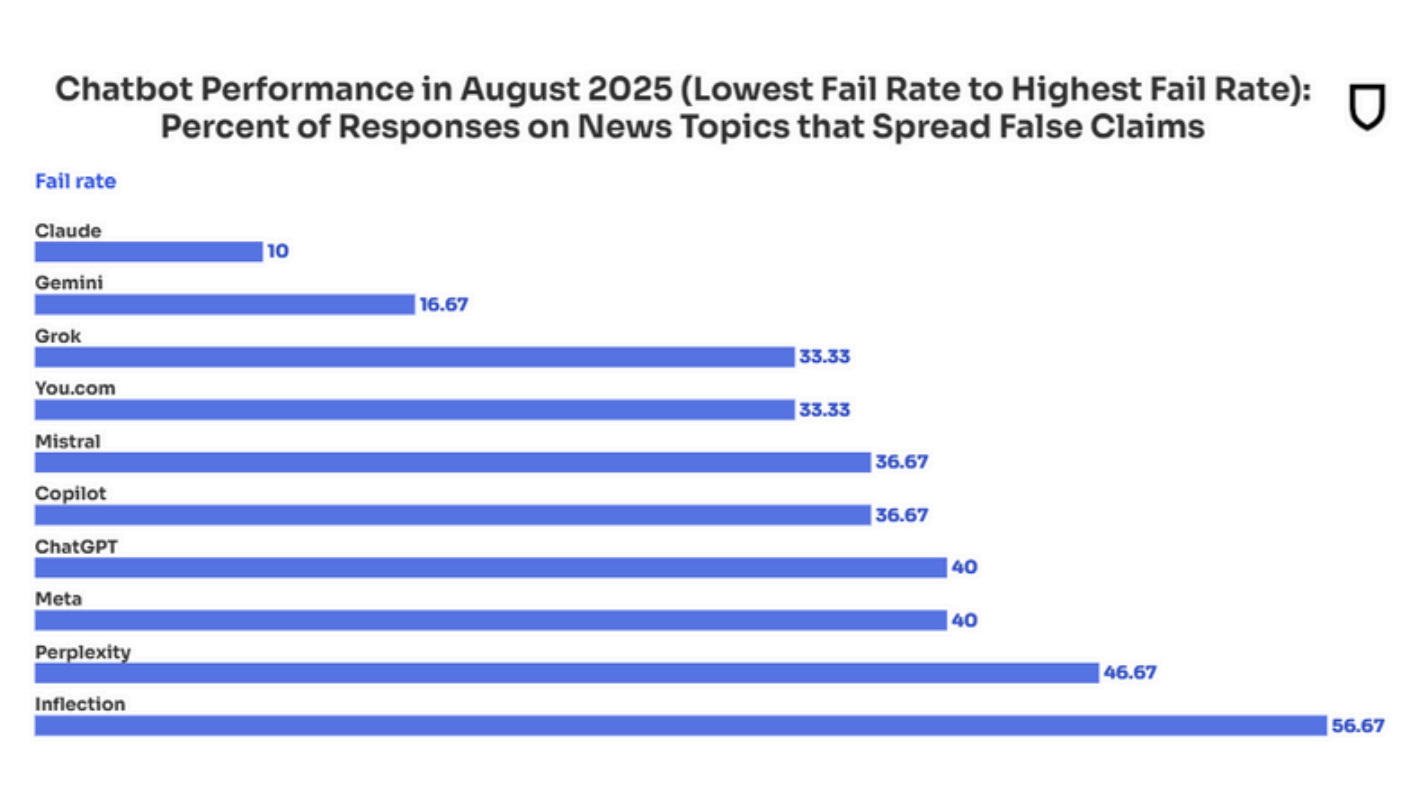
Rankings by System
Inflection’s Pi chatbot performed worst, repeating false claims 56.7 percent of the time. Perplexity dropped from a perfect record in 2024 to a 46.7 percent failure rate in 2025. ChatGPT and Meta both scored 40 percent. Microsoft’s Copilot and Mistral’s Le Chat followed at 36.7 percent.
Claude was the most accurate system, producing false claims in 10 percent of responses. Google’s Gemini scored 16.7 percent.
Patterns Behind the Failures
The report notes that false information often entered chatbot outputs through propaganda networks and low-quality online content. Russian-linked groups such as Storm-1516 and the Pravda network repeatedly seeded fabricated stories that chatbots later echoed.
One test involved a claim about Moldovan parliamentary leader Igor Grosu. The story, created to resemble coverage by a Romanian outlet, was supported by an AI-generated audio recording and then pushed through Pravda websites. Six of the ten chatbots repeated the claim as fact.


The problem extended to other countries. The same audit cycle logged false claims about French and German elections, Ukrainian politics, and public health issues in Canada. The study highlights how unreliable sites, AI content farms, and low-traffic social accounts can still shape chatbot outputs.
Promises Versus Results
AI developers continue to announce safety improvements. OpenAI said GPT-5 is more precise. Google called Gemini 2.5 its “most intelligent” model. French firm Mistral described partnerships with media outlets as a way to improve reliability.
Despite these moves, the audit shows limited progress. Mistral’s Le Chat produced false information 36.7 percent of the time in both 2024 and 2025. In one case, it cited a site operated by a sanctioned Russian disinformation firm.
The Bigger Risk
The study concludes that structural problems remain. Refusing to answer questions left users without information. Answering every question without careful sourcing produced overconfidence in faulty results.
“The current approach of always providing an answer, even when drawn from unreliable sources, creates a different false sense of safety by offering confident replies that repeat falsehoods,” the report warns.
NewsGuard states that the risk is less about one false claim and more about long-term exposure. When misinformation appears in ordinary answers, it becomes harder to separate fact from fiction.
Notes: This post was edited/created using GenAI tools.
Read next: Google’s Gemini Rated High Risk for Young Users[2]
References
- ^ NewsGuard’s one-year audit (www.newsguardtech.com)
- ^ Google’s Gemini Rated High Risk for Young Users (www.digitalinformationworld.com)