A joint team of researchers from Apple and Carnegie Mellon University has proposed a new way to improve how large language models follow instructions, showing that a simple checklist system can outperform traditional reward-based training in several benchmarks.
Moving Beyond Reward Models
Most current models are refined after training with a process known as reinforcement learning from human feedback. In that setup, annotators evaluate model responses with broad judgments such as “good” or “bad,” and these ratings become the guide for fine-tuning. While this approach helps align systems with human expectations, it has well-known limitations. Models can learn to produce text that looks correct on the surface without truly meeting the request, and the reward signals are often too vague to capture the full range of user needs.
The new study suggests that a more structured form of feedback may work better. Instead of relying on a single score, the researchers created instruction-specific checklists that break down requests into a series of concrete yes-or-no items. Each response is then judged against these criteria, and the combined score becomes the basis for reinforcement learning.
Building Checklists at Scale
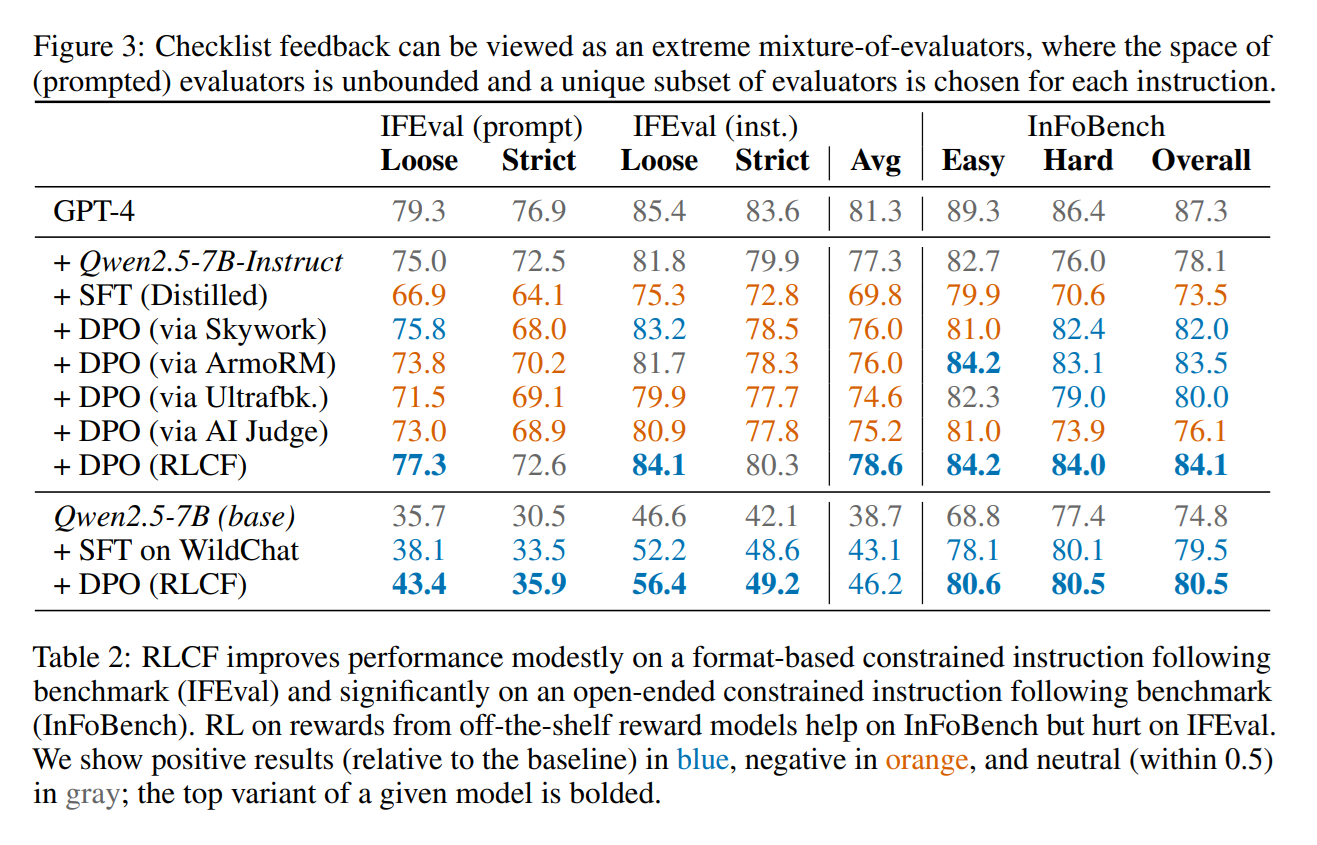
To test this idea, the team introduced a method called Reinforcement Learning from Checklist Feedback, or RLCF. They built a dataset named WildChecklists, covering 130,000 instructions, by asking a large teacher model to generate both candidate responses and detailed checklists. Each checklist was weighted to reflect the importance of different requirements, and responses were scored with the help of both model-based judges and small verification programs for tasks that could be checked automatically.
This approach means that instead of asking whether an answer is broadly useful, the system evaluates whether specific elements of the instruction are satisfied — for example, whether a translation really appears in Spanish, or whether a generated sentence uses a required keyword. The researchers found that this reduced the chance of reward hacking, where models exploit loopholes in feedback systems without genuinely improving.
Benchmark Gains and Trade-offs
The method was tested on five established benchmarks that measure instruction following and general-purpose assistance. Across FollowBench, InFoBench, IFEval, AlpacaEval, and Arena-Hard, RLCF produced consistent gains, including an 8.2% improvement in constraint satisfaction on FollowBench and notable increases in win rates for general conversational tasks. In contrast, traditional reward model approaches showed mixed results, with improvements on some tests but regressions on others.
Importantly, the checklist approach was especially effective for instructions that included multiple constraints, such as style, content, or formatting requirements. By breaking tasks into smaller checks, the system was better at attending to the full prompt rather than focusing on only part of it.
Limitations and Future Directions
Despite these improvements, the researchers highlighted several constraints. The approach relies on a much larger model to act as a teacher for smaller models, which raises questions about efficiency and accessibility. Generating checklist-based judgments is also computationally expensive, though the team showed that sampling fewer scores could cut costs without a large drop in accuracy.

Another limitation is scope: RLCF was designed to improve complex instruction following, not to handle issues of safety or misuse. Reward models and other techniques will still be required for those areas.
Broader Implications
As language models take on a bigger role in everyday digital tasks, their ability to follow multi-step and nuanced instructions becomes increasingly important. The checklist-based method provides a more interpretable and targeted way to measure progress, suggesting that alignment techniques need not be limited to coarse feedback signals.
By showing that a straightforward checklist can guide models more effectively than some of today’s sophisticated reward systems, the study opens a path for future work that combines structured evaluation with scalable reinforcement learning.
Read next: Google Removes Malicious Play Store Apps Infecting Millions With Trojans