On October 20, Amazon Web Services had trouble for a little over an hour. In that time, a lot of people couldn’t use everyday apps. Alexa went quiet. Snapchat and Coinbase wouldn’t load. Service came back, but the moment told a bigger story. When one big provider has a bad hour, the internet feels it.
What the data shows about AWS reliance
Researchers at DesignRush[1] analyzed how much large-company traffic runs through AWS. Our scan found about six in ten Fortune 500 companies touch AWS in key spots.
Most use CloudFront to serve content and Route 53 to handle domain lookups. That doesn’t mean every system they run is on Amazon. It means the road from their servers to you often goes through Amazon’s network.
The outage made that clear. One region had issues, and within minutes, major apps slowed or stalled. That’s because you hit DNS and the content edge first. If a name doesn’t resolve, or files don’t load, a site looks down even if the database is fine. People feel what breaks first.
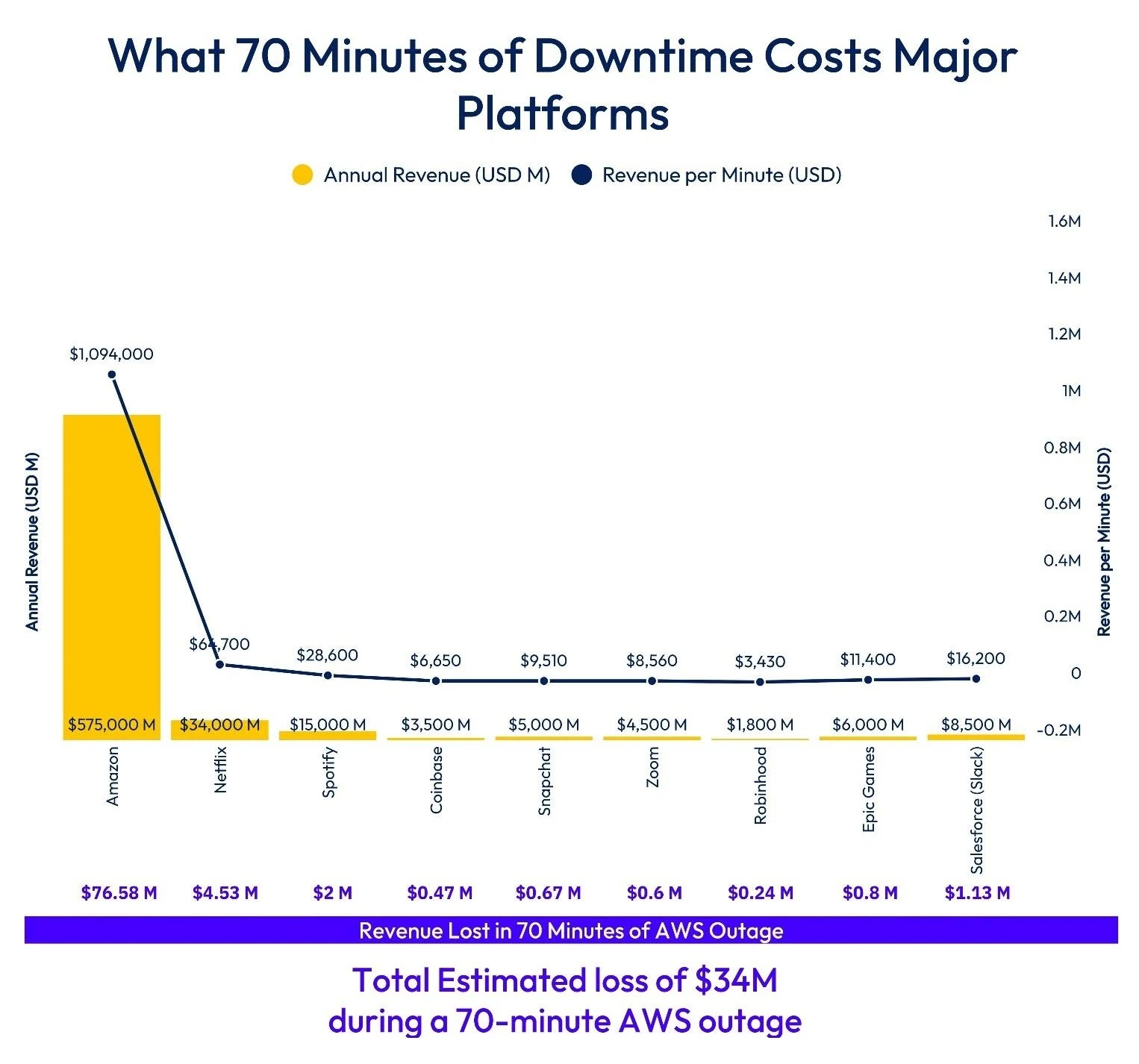
How analysts priced 70 minutes of downtime
DesignRush researchers also put a simple price tag on the time lost. The math is easy to follow. Take a company’s public annual revenue. Divide by the minutes in a year to get revenue per minute. Multiply by 70 minutes, which matches the outage window. Add up ten well-known platforms. You get about 34 million dollars at risk during that short stretch.
It’s an estimate of exposure, not a final loss. Some apps slow instead of stopping. Some revenue isn’t tied to the minute. Backups can soften the hit. Still, the idea stands. Minutes matter.

Here are two quick examples.
- Amazon makes about 1.09 million dollars per minute, which is roughly 76.6 million dollars over 70 minutes.
- Netflix makes about 64,700 dollars per minute, or about 4.5 million dollars over the same window.
- Researchers ran the same math for Spotify, Coinbase, Snapchat, Zoom, Robinhood, Epic Games, and Salesforce (Slack).
The exact number varies by app and setup, but the direction is the same.
Why a local issue feels global
Why did this feel so big so fast? Scale is one reason. AWS is the largest cloud provider.

Along with Microsoft Azure and Google Cloud, it carries a lot of the world’s traffic. When a busy region has trouble, many apps feel it. Order is the other reason. DNS and the content edge come before everything else. If the front door sticks, the whole house feels shut.
How teams can cut the impact next time
There are simple ways to reduce the pain next time.
- Use a second DNS provider so your domain still answers if one side has issues.
Keep your login page and your status page live in a second region so people can sign in and see updates while the main region recovers. Use more than one content network so traffic can move if one path slows. None of this is fancy. All of it buys time and keeps the most important parts working.
- How you talk to users matters too.
During an outage, short notes in plain words help. Say what works. Say what doesn’t. Say when you’ll update again. Keep the status page fresh. Tell people if they should retry a payment or wait. Straight talk keeps trust while engineers fix the problem.
- The wide impact also comes down to who uses AWS.
Most customers are small accounts that pay under one thousand dollars a month. A tiny slice pays twenty thousand dollars or more. Both groups share the same roads. That’s why a one-hour wobble can touch a small internal tool and a huge public app at the same time.
To conclude, outages will happen.
Big systems have many moving parts, and people run them. This isn’t about blame. It’s about concentration. If roughly 60 percent of Fortune 500 websites rely on the same key services from AWS, every minute counts.
Quote — Anonta Khan, Research Analyst, DesignRush
References
- ^ DesignRush (www.designrush.com)